
The Comprehensive LLMs Development Lifecycle

Introduction
Welcome to our comprehensive guide on the lifecycle of Large Language Models (LLMs). This series will take you on an in-depth exploration of LLMs, which have become a transformative force in AI, revolutionising how we interact with and leverage language technology. Whether you're an experienced AI practitioner or a curious newcomer, this guide will enrich your understanding of LLMs from inception to deployment.
In today’s journey, you will explore:
The foundational phases of LLM development.
The intricacies of model selection and adaptation.
Advanced fine-tuning techniques.
Evaluation metrics and deployment strategies.
Real-world applications and future directions.
The LLMs Lifecycle: From Idea to Production
The figure below represents a typical LLMs project lifecycle.
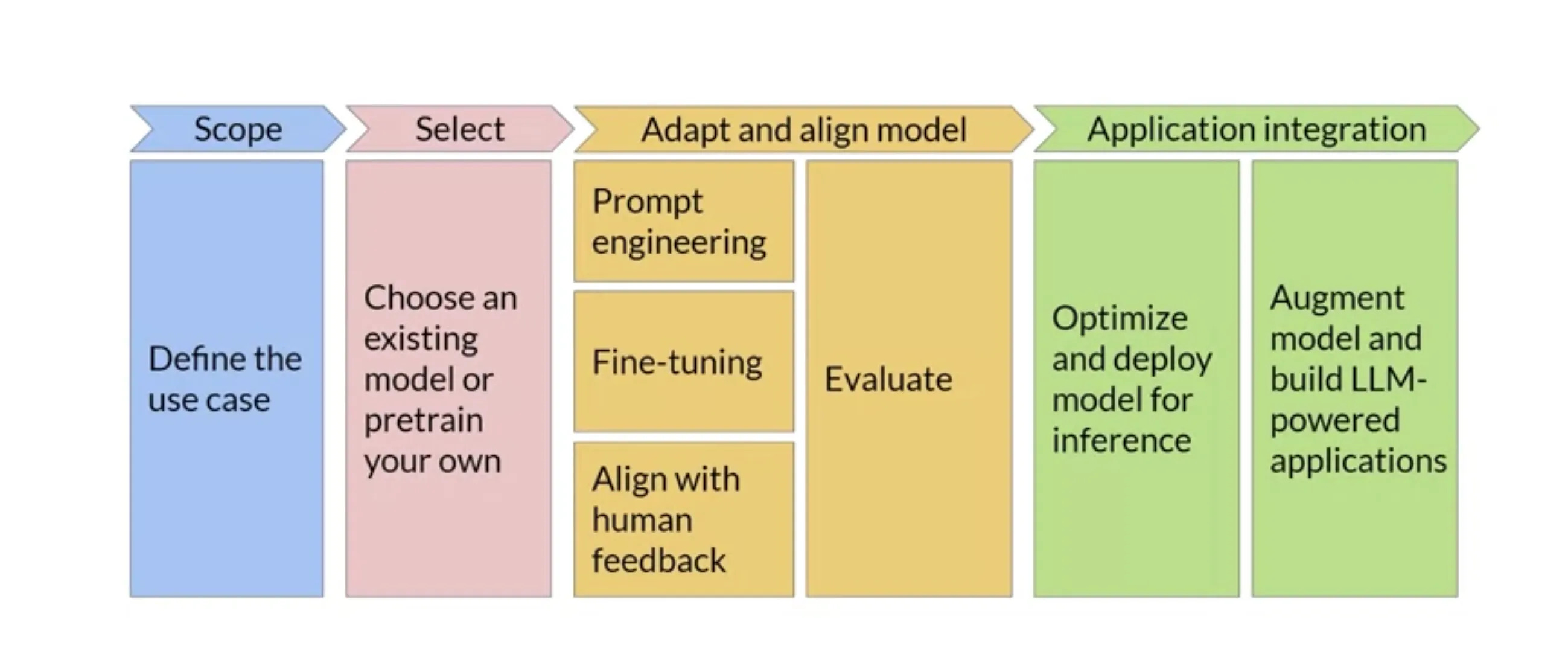
Defining Use Cases: The Scope Phase
The lifecycle of a Large Language Models (LLMs) project begins with a critical phase: defining use cases. This scoping phase is essential as it establishes the foundation for the entire project, pinpointing the core objectives and desired outcomes. Whether the goal is natural language generation, text summarisation, or more specialised applications like creative writing, this phase ensures that the project is strategically aligned with broader business objectives.
Key Considerations:
Strategic Alignment: The LLM project must integrate seamlessly with the overarching business goals, contributing meaningfully to long-term strategies. This alignment ensures that the LLM's development and deployment are not just technologically sound but also beneficial to the organisation’s mission.
Target Audience Analysis: A deep understanding of the end-users or stakeholders is crucial. This understanding informs the functionality of the LLM, ensuring it meets the specific needs and expectations of its intended audience.
Application Domains: Identifying the specific domains where the LLM will be applied—such as legal, healthcare, or customer service—is vital. This choice influences the model's design and the training data it will require, as different domains present unique challenges and opportunities.
Challenges:
Granular Specification: One of the major challenges in this phase is clearly defining the scope without falling into the trap of overgeneralisation. A poorly defined scope can lead to a lack of focus, making the project inefficient and resource-intensive.
Stakeholder Expectations: Balancing the technical feasibility of the LLM with the expectations of stakeholders is another critical challenge. Stakeholders may have varying levels of understanding of LLM capabilities, and managing these expectations while delivering a technically sound product is essential for the project's success.
In this phase, the careful definition of use cases sets the stage for a successful LLM project, guiding the subsequent stages of model selection, training, and deployment.
Model Selection or Pre-training: Building the Foundation
After defining the scope of your LLM project, the next crucial step is selecting the right model architecture or deciding whether to pre-train a custom model. This decision is foundational, as it shapes the project's trajectory, influencing resource allocation, timeline, and the level of customisation possible.
Key Steps:
Leveraging Pre-trained Models: Opting for existing models like those available on Hugging Face can dramatically reduce time-to-market, allowing you to build on proven architectures.

Fig. 2 Hugging Face Pre-training Custom Models: For projects with unique domain-specific requirements, pre-training a model from scratch on custom datasets ensures the LLM is tailored precisely to your needs.

Technical Considerations:
Architecture Selection: Choosing between architectures like GPT, BERT, or T5 depends on the task at hand. T5, for example, excels in text-to-text tasks, making it a versatile choice for generative applications.
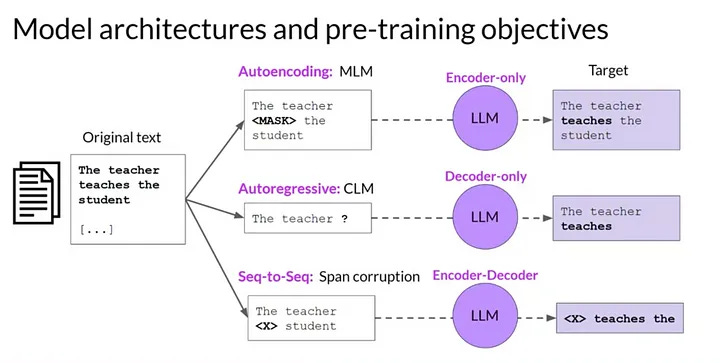
Fig. 3 Brief of Model Architectures Computational Resources: Pre-training a model is resource-intensive. It’s essential to weigh the computational demands against the performance gains, as this process requires significant computational infrastructure.
Challenges:
Domain Adaptation: A key challenge is ensuring that the selected or pre-trained model can effectively adapt to the linguistic and contextual nuances of the target domain. This involves not just selecting the right architecture but also fine-tuning it appropriately.
Resource Management: Balancing the substantial costs associated with pre-training large models against the potential benefits is another challenge. While a highly specialised LLM can offer significant advantages, careful consideration of resource allocation is required to ensure that the investment is justified.
In this phase, the choices you make regarding model selection or pre-training will lay the groundwork for the entire project, influencing everything from technical execution to final application performance.
Refining and Validating the Model: Adaptation, Alignment, and Evaluation
Once the model is selected or pre-trained, it enters a critical phase of refinement and validation to ensure it meets the specific requirements of the project. This phase involves adapting the model through fine-tuning, aligning its outputs with the project’s goals, and rigorously evaluating its performance to ensure it meets the desired standards.
Adaptation and Alignment
The adaptation and alignment of the model are essential to transforming a general-purpose model into one that performs exceptionally in its intended context. Here’s how this process unfolds:
Prompt Engineering: Crafting and refining prompts are vital to guiding the model toward producing relevant outputs. This process isn’t just about finding the right words; it requires a deep understanding of the model’s architecture and the specific goals of the project. Effective prompt engineering can significantly optimise the model’s performance, particularly in tasks that require precise and context-aware outputs.
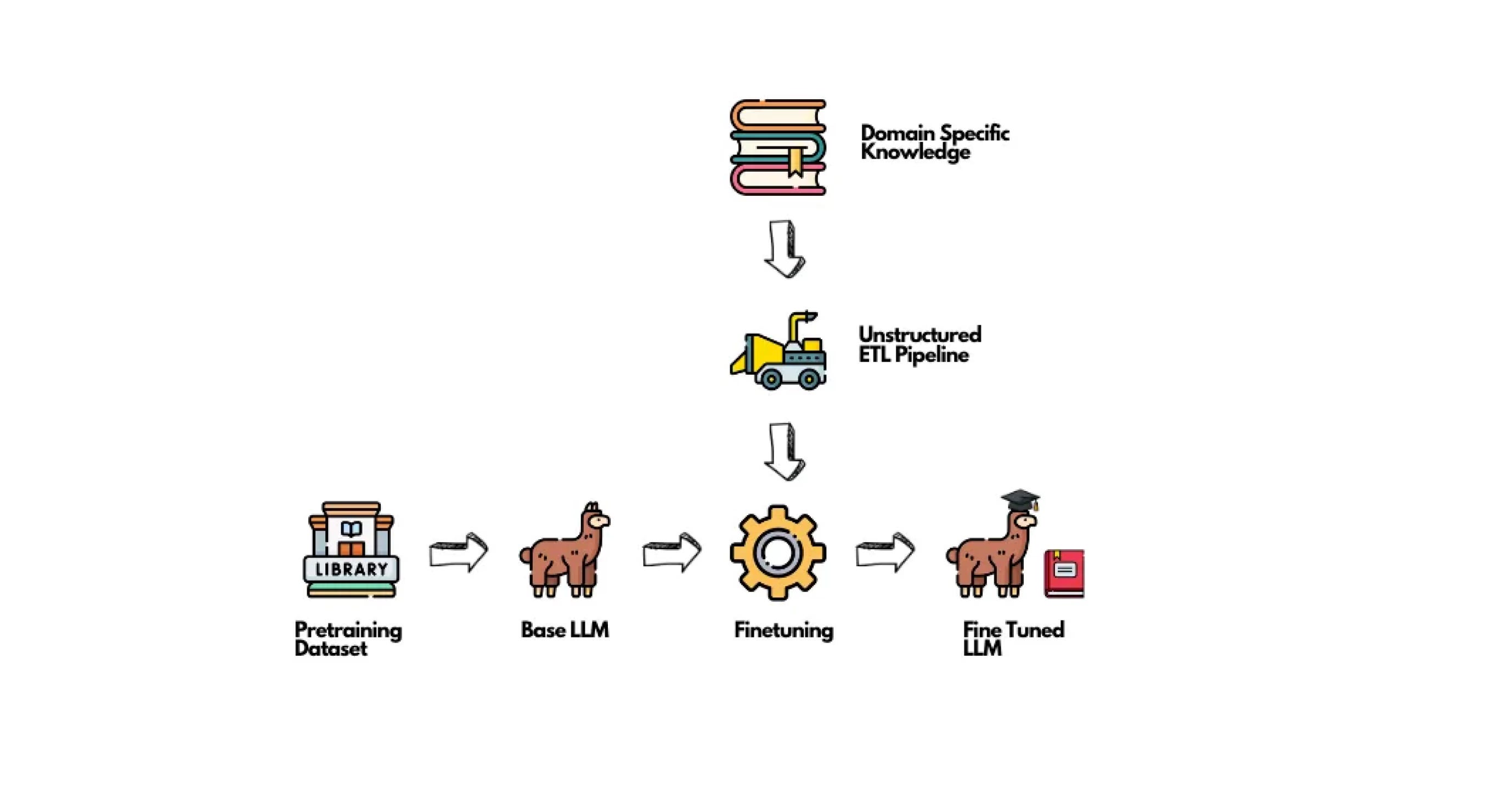
Fine-Tuning: Fine-tuning is the process of further training the model on domain-specific data to enhance its accuracy and relevance. This step is crucial for bridging the gap between a general-purpose model and one that is finely tuned for a particular application. It requires careful calibration to avoid overfitting—where the model becomes too tailored to the training data and loses its ability to generalise. The fine-tuning process is delicate and demands a balance between improving performance on specific tasks and maintaining the model’s overall versatility.

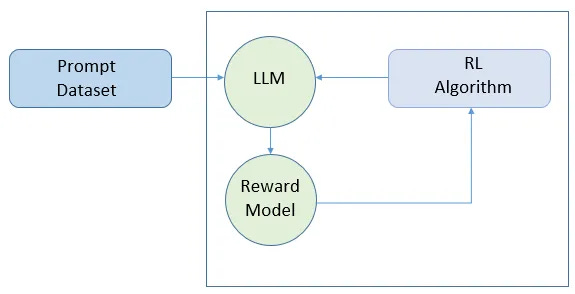
Fig.5 Fine-tuning Reinforcement Learning from Human Feedback (RLHF): RLHF is a sophisticated method that involves using human feedback to refine the model iteratively. This approach is particularly valuable in applications where the model’s outputs must closely align with human judgment, such as in creative content generation or interactive AI systems. By continuously incorporating human feedback, the model learns to reduce errors and produce outputs that are more consistent with human expectations. This iterative process not only improves accuracy but also enhances the model's ability to generate responses that are contextually appropriate and aligned with user preferences.
Evaluation Techniques
Evaluating the refined model is a multi-faceted process that involves both automated metrics and human judgment to ensure a comprehensive assessment of its performance.
Automated Metrics: The initial phase of evaluation often involves automated metrics like BLEU, ROUGE, and similar measures. These metrics provide a quantitative assessment of the model’s output quality, particularly in tasks involving text generation. However, these metrics typically focus on surface-level similarities, such as word overlap, and may not fully capture the deeper semantic accuracy or the context-sensitivity of the model’s outputs. While they are useful for benchmarking, they offer a limited view of the model’s true capabilities.
Human Evaluations: Given the limitations of automated metrics, human evaluations play a critical role in assessing the model’s performance. Human evaluators can provide insights into aspects of the model’s output that are more qualitative, such as creativity, coherence, and relevance. These evaluations are essential for understanding how well the model performs in real-world scenarios, where nuance and contextual understanding are key. However, human evaluations also introduce subjectivity, which can lead to variability in the assessment outcomes.
Benchmarking Against Standards: To ensure a comprehensive evaluation, it’s crucial to benchmark the model against established standards like GLUE (General Language Understanding Evaluation) and HELM (Holistic Evaluation of Language Models). These benchmarks provide a broad assessment of the model’s capabilities across various tasks, offering a standardised framework for comparison with other models. Benchmarking helps identify areas where the model excels and where further refinement is needed, guiding future development efforts.
Challenges
Despite the sophisticated techniques involved in refining and evaluating the model, several challenges must be addressed to ensure success.
Data Availability and Quality: Access to high-quality, domain-specific data is often a significant bottleneck in the adaptation and alignment process. The effectiveness of fine-tuning depends heavily on the quality and representativeness of the training data. Without sufficient and relevant data, the model may fail to achieve the desired performance improvements.
Scalability of Feedback Integration: As the model scales, integrating human feedback efficiently becomes increasingly complex. This challenge is particularly pronounced in applications that require real-time interactions or large volumes of data processing. Ensuring that the model maintains high performance while incorporating continuous feedback is a delicate balancing act that requires robust infrastructure and scalable processes.
Metric Limitations and Subjectivity: Automated metrics, while valuable, have inherent limitations in capturing the full range of linguistic nuances. They may not always correlate with human judgments of quality, which can lead to discrepancies in evaluation outcomes. On the other hand, human evaluations, while richer in detail, introduce subjectivity, which can result in inconsistent assessments. Balancing these two approaches is crucial for developing a robust evaluation strategy that accurately reflects the model’s capabilities.
In this phase of the LLM lifecycle, the focus is on ensuring that the model not only meets but exceeds the project’s requirements. By carefully adapting, aligning, and rigorously evaluating the model, you can achieve a level of refinement that ensures optimal performance in real-world applications.
Application Integration: Deploying and Scaling
With the LLM fine-tuned and evaluated, the next step involves integrating it into real-world applications. This phase focuses on optimising the model for deployment, ensuring it operates efficiently and effectively in a production environment.
Deployment Strategies:
Model Optimization: Techniques like distillation, quantisation, and pruning are employed to reduce the model's size and improve inference speed without compromising on accuracy.
Distillation: Training a smaller model (student) to mimic a larger, more complex model (teacher), thus making the model more efficient for deployment.
Quantisation: Reducing the precision of model weights to decrease the computational load, enabling faster inference times.
Pruning: Removing non-essential weights from the model to streamline its architecture, which helps in reducing latency during inference.
Augmentation for Enhanced Performance: Utilizing methods like Retrieval-Augmented Generation (RAG) to supplement the model’s outputs with up-to-date external knowledge, addressing limitations such as outdated information or hallucinations.
RAG Implementation: RAG combines LLMs with retrieval systems that pull in the latest information from external databases, ensuring that the model’s outputs are both accurate and current.
Chain-of-Thought Prompting: Encouraging models to generate intermediate reasoning steps before arriving at a final answer, thereby reducing the likelihood of errors or hallucinations.
Challenges:
Operational Scalability: Ensuring that the LLM can handle real-world demands, such as high query volumes or complex, multi-turn interactions.
Maintenance of Relevance: Continuously updating the model to reflect new information and maintain accuracy over time, particularly in dynamic fields.
Conclusion
The lifecycle of an LLM project is an intricate and multifaceted process that demands meticulous attention to detail across all phases—from the initial scoping of use cases to the ongoing optimisation of a deployed model. Each phase is interdependent, meaning that decisions made early in the project can have far-reaching implications on the success and efficiency of later stages.
The initial phase, where use cases are defined, is particularly crucial as it lays the groundwork for the entire project. Misalignment with business goals or a poorly understood target audience can lead to a model that fails to deliver value. Similarly, the choice between leveraging pre-trained models and custom pretraining has a profound impact on project timelines, resource allocation, and the model's adaptability to specific tasks.
As the project progresses to model refinement and validation, the focus shifts to ensuring that the model meets the defined requirements. This phase is where the real "magic" happens—transforming a generic language model into a tool that excels in its intended application. However, this transformation is far from straightforward; it requires careful prompt engineering, fine-tuning, and the integration of human feedback, all of which are critical to aligning the model’s outputs with human expectations.
The final phase—deployment and scaling—demands a different set of considerations. The technical challenges of optimising the model for real-world applications, ensuring operational scalability, and maintaining the model's relevance over time are paramount. Neglecting this phase can lead to performance bottlenecks, user dissatisfaction, or even failure to meet regulatory standards in certain industries.
In summary, the success of an LLM project hinges on a holistic approach that integrates strategic foresight with technical expertise. Organisations that manage to navigate these complexities effectively are not just deploying an LLM—they are setting the stage for sustained innovation and competitive advantage.
Future Directions
LLMOps for Continuous Improvement
As the use of LLMs becomes more widespread, the need for robust operational strategies—collectively known as LLMOps—will become increasingly critical. LLMOps extends the principles of MLOps (Machine Learning Operations) to the unique challenges posed by large language models. This includes the continuous monitoring, maintenance, and enhancement of LLM performance over time.
One of the key aspects of LLMOps is monitoring. In production, models must be constantly monitored to detect any drifts in performance, such as a decline in accuracy due to shifts in the input data distribution (also known as data drift) or changes in the underlying domain knowledge. Early detection of such issues allows for timely interventions, such as retraining or fine-tuning, to restore the model's performance.
Another critical component is maintenance. Unlike traditional software, which can be static once deployed, LLMs require continuous updates. This could involve retraining the model with new data to ensure it remains current, especially in dynamic fields like finance or healthcare. Maintenance also includes managing the model’s dependencies and ensuring compatibility with the latest infrastructure and tools.
Enhancement involves the iterative improvement of the model's capabilities. As user feedback and new data become available, these can be used to fine-tune the model further, enhancing its accuracy, relevance, and user satisfaction. This process is particularly important in applications where the model interacts with end-users, as it helps to align the model’s outputs more closely with human expectations.
Implementing effective LLMOps is not just a technical challenge; it also requires a cultural shift within organisations. Teams must adopt a mindset of continuous improvement, where models are seen as evolving assets that need regular attention and refinement. By embracing LLMOps, organisations can ensure their models remain robust, reliable, and aligned with business objectives over the long term.
Interdisciplinary Approaches
The future of LLMs will likely be shaped by interdisciplinary approaches that draw on insights from cognitive science, machine learning, data engineering, and even fields like neuroscience and linguistics. These approaches can lead to the development of more advanced, adaptable, and interpretable LLMs, pushing the boundaries of what these models can achieve.
Cognitive Science: By studying how humans acquire, store, and retrieve knowledge, researchers can develop models that mimic these processes, potentially leading to LLMs that are not only more efficient but also more aligned with human reasoning patterns. Cognitive science can inform the design of models that better understand context, manage ambiguity, and reason about complex scenarios.
Neuroscience: Insights from neuroscience could inspire new architectures that mirror the brain’s structure and functioning, particularly in how memories are formed and retrieved. This could lead to the creation of models with more human-like understanding and recall abilities, improving their performance in tasks that require deep contextual understanding or long-term memory.
Linguistics: Understanding the nuances of human language is critical for developing LLMs that can engage in more natural and meaningful interactions. Linguistic theories can inform the design of models that better grasp syntax, semantics, and pragmatics, leading to more accurate and context-aware language generation.
Data Engineering: The ability to handle and process massive datasets efficiently is a cornerstone of LLM development. Advances in data engineering will continue to play a crucial role in the scalability and efficiency of LLMs. This includes innovations in data pipelines, distributed computing, and storage solutions that can manage the immense volumes of data required to train and maintain these models.
Incorporating these interdisciplinary insights can help address some of the current limitations of LLMs, such as their tendency to generate biased or nonsensical outputs or their struggle with tasks requiring deep reasoning. By breaking down the silos between disciplines, researchers and practitioners can develop LLMs that are not only more powerful but also more reliable, ethical, and aligned with human values.
In conclusion, the future of LLMs lies in a continuous cycle of refinement, driven by robust operational practices and enriched by interdisciplinary collaboration. Organisations that invest in these areas will be well-positioned to harness the full potential of LLMs, driving innovation and achieving strategic goals in an increasingly AI-driven world.
References
[1] Zheng, J., Qiu, S., Shi, C., & Ma, Q. (2024). Towards Lifelong Learning of Large Language Models: A Survey. arXiv preprint arXiv:2406.06391.
[2] Cao, B., Lin, H., Han, X., & Sun, L. (2024). The life cycle of knowledge in big language models: A survey. Machine Intelligence Research, 21(2), 217-238.
[3] Hugging Face
[4] Generative AI Project Lifecycle
[5] The Lifecycle of a GenAI Project
[6] The Generative AI LLM Project Lifecycle: From Inception to Application
[7] Fine-Tuning GPT 3.5 with Unstructured: A Comprehensive Guide