
The Role of Large Language Models in Crafting AIDT: Simulating Human Activities and Beyond
An In-depth Look at the Creation of Generative Agents and the Generation of Synthetic Data

Welcome to our LHP AI Digital Twin (AIDT) newsletter. In today’s journey, we will continue to delve into the fascinating world of AIDTs, exploring the potential of Large Language Models (LLMs) in simulating human activities and generating synthetic data. In this issue, you will discover:
Introduction: A brief overview of the concept of AIDT and the purpose of this in-depth exploration.
Understanding LLMs: An explanation of what LLMs are and their capabilities, as well as a brief mention of notable LLMs like GPT-4 and Llama.
Simulating Human Activities with LLMs: A discussion on how LLMs can be used to simulate human activities, with an introduction to the concept of generative agents.
Creating Generative Agents: A detailed walkthrough of creating a generative agent using LangChain's implementation, including defining initial memories and traits.
Generating Synthetic Data: An explanation of how LLMs can generate diaries or logs as synthetic data for AIDT, with a discussion on the importance of this synthetic data in creating AIDT.
Introduction
In artificial intelligence, one concept that has been making waves is the idea of AIDT. These are virtual replicas of processes, systems, or entities created and maintained to mirror their real-world counterparts. AIDT bridge the physical and digital worlds, allowing for detailed analysis, simulations, and potential predictions.

In the previous AIDT video, we explored the possibility of LLMs generate synthetic data for these AIDTs. In this article, we will delve deeper into the concept of using LLMs to simulate human activities, creating a rich tapestry of synthetic data that can be used to build and enhance AIDT. We'll explore cutting-edge research in this field, discuss a practical implementation, and look at potential real-world applications. So, let's embark on this exciting journey together.
Understanding Large Language Models (LLMs)
LLMs are a type of artificial intelligence model designed to understand and generate human-like text. They are trained on vast amounts of data and can generate coherent, contextually relevant sentences by predicting the likelihood of a word given the previous words used in the text.

The capabilities of LLMs are truly remarkable. They can answer questions, write essays, summarise texts, translate languages, and even generate creative content like poetry or stories. But beyond these, LLMs can be used to simulate human-like conversations and activities, making them an invaluable tool in the creation of AIDT.
The evolution of LLMs has been rapid and transformative. Starting from the introduction of the attention mechanism [1] in 2014, which led to the development of the transformer model [2] in 2017, we've seen the emergence of several influential models. Some of the most notable ones include the generative pre-trained transformer series (GPT) and bidirectional encoder representations from transformers (BERT) [3], both of which are based on the transformer model.
In recent years, we've seen the release of several powerful LLMs. GPT-3 [4], released by OpenAI in 2020, boasts more than 175 billion parameters and uses a decoder-only transformer architecture. Its successor, GPT-4, released in 2023, is a multimodal model that can process and generate both language and images. It has demonstrated human-level performance in multiple academic exams and powers Microsoft Bing search.
Another notable LLM is Large Language Model Meta AI (Llama), released by Meta in 2023. Llama, with its largest version having 65 billion parameters, used a transformer architecture and was trained on a variety of public data sources, including webpages from CommonCrawl, GitHub, Wikipedia, and Project Gutenberg. Llama has also spawned several descendants, including Vicuna and Orca, further expanding the ecosystem of LLMs.
These models showcase the versatility and power of LLMs. In the context of our discussion, we're particularly interested in how LLMs can be used to simulate human activities and generate synthetic data for AIDT. As we'll see, this opens up a world of possibilities for creating realistic, interactive digital replicas of human beings.
Simulating Human Activities with LLMs
One of the most exciting applications of LLMs is their ability to simulate human activities. By understanding and generating human-like text, LLMs can mimic human thought processes and interactions, creating a realistic simulation of human activities. This capability is particularly valuable in the creation of AIDT, where the goal is to create a virtual replica that behaves as closely as possible to its real-world counterpart.
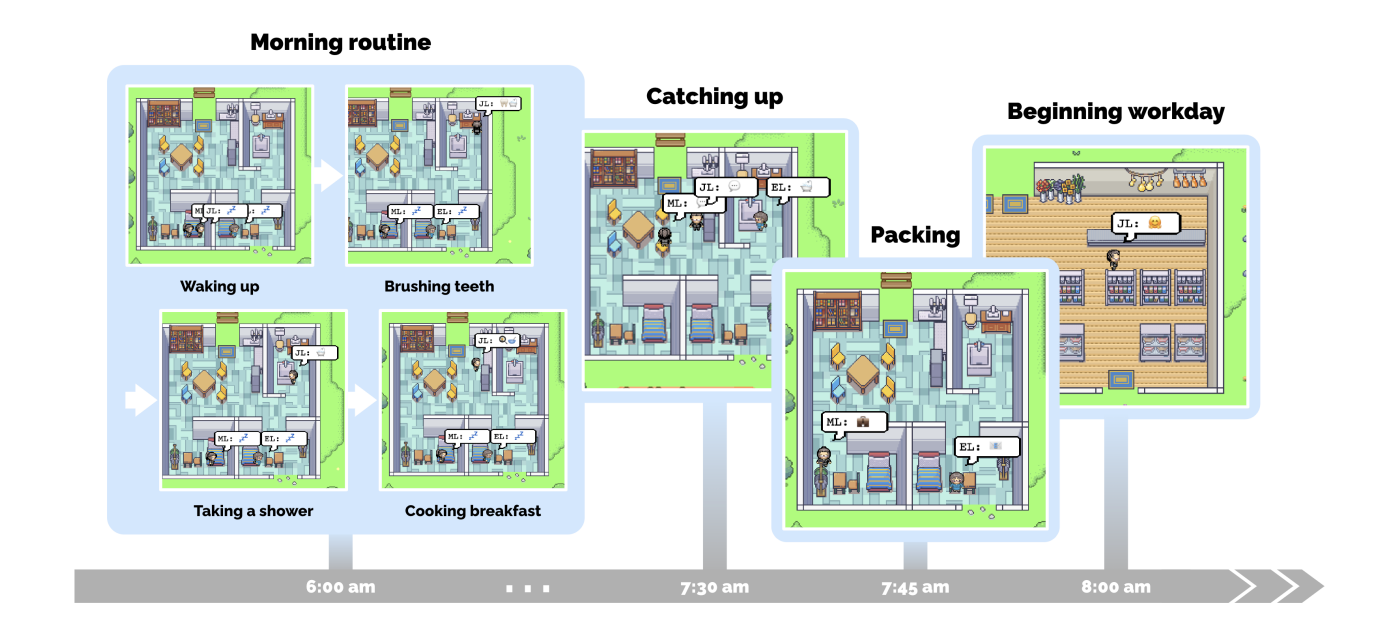
By predicting the likelihood of a word given the previous words used in the text, LLMs can generate coherent, contextually relevant sentences that mimic human-like conversation. However, their capabilities extend beyond text generation. They can be used to simulate a wide range of human activities, from simple tasks like cooking breakfast to complex behaviours like planning and decision-making.
This is where the concept of generative agents comes into play. Introduced in the paper "Generative Agents: Interactive Simulacra of Human Behavior" by Joon Sung Park et al. [5], generative agents are computational software agents that simulate believable human behaviour. They extend the LLM to store a complete record of the agent’s experiences using natural language, synthesise those memories over time into higher-level reflections, and retrieve them dynamically to plan behaviour.

Generative agents can wake up, cook breakfast, and head to work; artists paint while authors write; they form opinions, notice each other, and initiate conversations; they remember and reflect on days past as they plan the next day. The potential applications of these generative agents are vast, from role-play and social prototyping to virtual worlds and games.
An interesting demo of the implementation of Generative agents can be found here!
A practical implementation of this concept can be seen in the work of QuangBK’s group, based on the implementation of the Langchain Generative Agents. They improve and add more features to make it as similar to the original paper , they improve and add more features to make it like the original paper as much as possible. His implementation showcases how generative agents can think, plan, make decisions, and interact with others, providing a glimpse into the future of AIDT.
In essence, LLMs and generative agents open up a world of possibilities for simulating human activities. They allow us to create realistic, interactive digital replicas of human beings, which can be used to generate synthetic data for AIDT.
Creating Generative Agents
Generative agents are a type of AI that can interact with their environment and other agents. They can remember past interactions, learn from them, and use this knowledge to guide their future behaviour. In this section, we will walk you through the process of creating a generative agent using the Generative Agents in LangChain implementation.
Detailed Walkthrough
The first step in creating a generative agent is defining its initial memories and traits. These memories and traits will guide the agent's behaviour and interactions with its environment and other agents. In the LangChain implementation, memories are stored in a single stream and can come from dialogues or interactions with the virtual world. These memories are then retrieved using a weighted sum of salience, recency, and importance.
Here is a code sample that demonstrates how to create a generative agent:
from langchain_experimental.generative_agents import (
GenerativeAgent,
GenerativeAgentMemory,
)
tommies_memory = GenerativeAgentMemory(
llm=LLM,
memory_retriever=create_new_memory_retriever(),
verbose=False,
reflection_threshold=8,
)
tommie = GenerativeAgent(
name="Tommie",
age=25,
traits="anxious, likes design, talkative",
status="looking for a job",
memory_retriever=create_new_memory_retriever(),
llm=LLM,
memory=tommies_memory,
)
print(tommie.get_summary())In this example, we first define the LLM and create a new memory retriever. We then create a generative agent named "Tommie" who is 25 years old, anxious, likes design, is talkative, and is currently looking for a job. We also define a memory for Tommie using the ‘GenerativeAgentMemory’ class.
Interactions with Environment and Other Agents
Generative agents interact with their environment and other agents through observations and dialogues. When an agent makes an observation, it stores the memory and scores its importance. When an agent responds to an observation, it generates queries for the retriever, fetches documents based on salience, recency, and importance, summarises the retrieved information, and updates the last accessed time for the used documents.
Here is a more detailed code sample that demonstrates how an agent can interact with its environment:
tommie_observations = [
"Tommie remembers his dog, Bruno, from when he was a kid",
"Tommie feels tired from driving so far",
"Tommie sees the new home",
"The new neighbors have a cat",
"The road is noisy at night",
"Tommie is hungry",
"Tommie tries to get some rest.",
]
for observation in tommie_observations:
tommie.memory.add_memory(observation)
print(f"Tommie's memory: {tommie.memory.get_memory()}") Name: Tommie (age: 25)
Innate traits: anxious, likes design, talkative
Tommie is a person who is observant of his surroundings, has a sentimental side, and experiences basic human needs such as hunger and the need for rest. He also tends to get tired easily and is affected by external factors such as noise from the road or a neighbor's pet.In this example, we add several observations to Tommie's memory. These observations will influence Tommie's future behaviour and interactions. We also print out Tommie's memory after each observation to track how it changes over time.
Generative agents can also interact with other agents. For example, they can have conversations with other agents, ask them questions, and respond to their questions. These interactions are also stored in the agent's memory and can influence its future behaviour.
Generating synthetic data
LLMs can be used to generate synthetic data, such as diaries or journals, which can be used to create AIDT. This synthetic data helps to simulate human activities and behaviours, which is essential for creating realistic interactive digital replicas of humans.
Generating diaries or journals
One of the ways in which LLM generates synthetic data is to simulate the activities of the generating agent and record these activities as diary or log entries. These entries can include the agent's thoughts, actions, interactions, and observations. They provide a detailed record of the agent's behaviour and can be used to train AIDT.
The following demonstrates diary entries generated by a generative agent:

In this example, we define a new day for Tommie and a list of activities for that day. We then add each activity to Tommie's memory and generate diary entries for it.
The Importance of Synthetic Data
Synthetic data plays a crucial role in creating an AIDT. It provides a rich source of information that can be used to train AI to mimic human behaviour. By generating synthetic data that approximates human activities, we can create more realistic and interactive AIDT.
In addition, synthetic data allows us to simulate a variety of scenarios and behaviours that may not be possible with real-world data. This makes it an important tool for testing and improving the performance of AIDT.
In short, LLM's ability to generate synthetic data opens up endless possibilities for creating AIDT. By simulating human activities and generating detailed diary or log entries, we can create realistic interactive digital replicas of humans.
References
[1] Niu, Z., Zhong, G. and Yu, H., 2021. A review on the attention mechanism of deep learning. Neurocomputing, 452, pp.48-62.
[2] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł. and Polosukhin, I., 2017. Attention is all you need. Advances in neural information processing systems, 30.
[3] Devlin, J., Chang, M.W., Lee, K. and Toutanova, K., 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[4] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A. and Agarwal, S., 2020. Language models are few-shot learners. Advances in neural information processing systems, 33, pp.1877-1901.
[5] Park, J. S., O’Brien, J. C., Cai, C. J., Morris, M. R., Liang, P., & Bernstein, M. S. (2023). Generative Agents: Interactive Simulacra of Human Behavior. arXiv preprint arXiv:2304.03442.